I left an AI agent colony running for a week. Nobody was using it. Zero requests. Zero tasks. Just a queen and a couple of workers sitting in an empty room, doing what they do when nobody's watching.
When I came back, the colony had eaten 4.5 GB of RAM.
This is the story of how that happened, why I should have seen it coming, and what it taught me about the difference between data that matters and data that doesn't.
Three Charts That Tell the Whole Story
The monitoring dashboard gave me three charts. Together they paint a picture that's almost comical in how obvious the problem is, once you see it.
Here's what memory looked like over that week:
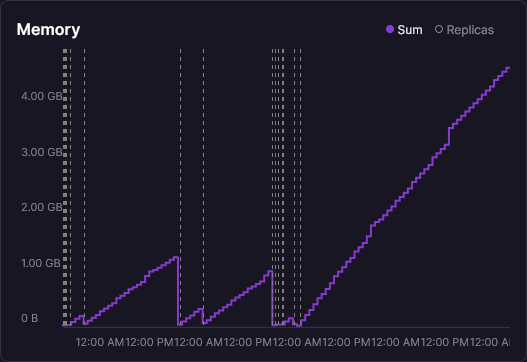
That's about as textbook a memory leak as you'll ever see. A straight line heading northeast. You can see a few container restarts early on (the drops back to zero), but after the last restart it's just an unbroken climb. Roughly 270 MB per day.
Now here's what network traffic looked like during the same period:
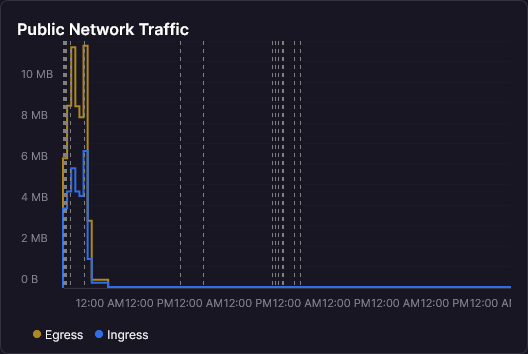
That spike on the left? That's me deploying and testing the colony. Everything after that is a flatline. Zero ingress. Zero egress. Nobody home.
And here's the one that really bugged me. CPU:
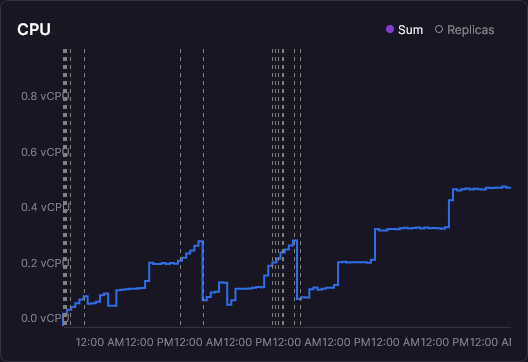
Not just non-zero, but increasing. A staircase pattern, stepping up from near zero to half a vCPU. For a service doing nothing. That staircase is the clue that something is growing over time and making routine operations progressively more expensive.
The math turned out to be pretty simple once I understood what was happening. But let me set the stage first.
Formicary is a stigmergic multi-agentic coordination framework. Agents coordinate through environmental signals, like pheromones, that decay over time. It's inspired by how ant colonies work. No central orchestrator telling everyone what to do. Instead, agents read the environment, act on what they find, and leave signals for others.
At the heart of every colony is the queen. She's not a micromanager. She monitors colony health, tracks worker performance, detects drift. And she does this by emitting signals. A coordination signal every cycle. Heartbeat signals for agent liveness tracking. These are housekeeping signals. They exist so the colony knows it's alive.
The queen runs on a one-second tick. Every second: emit a coordination signal, emit heartbeats, check on workers, prune decayed signals. Even when nobody's home.
Two signals per second. Roughly four event-log entries per second (stores, then later prunes). Each entry around 800 bytes. That's 3,200 bytes per second, 276 MB per day, about 2 GB over a week. Which maps almost exactly to what the monitoring showed.
The System Was Working As Designed. That's the Problem.
Nothing was broken in the traditional sense. Every component was doing exactly what it was supposed to do. The queen emitted signals. The signal bus stored them. The decay processor pruned them. The event store recorded the history. Each piece was correct. The system as a whole was not.
Formicary uses an event-sourced storage layer called LumineDB. Event sourcing is an append-only pattern. You never update or delete rows. You write immutable events: "signal deposited," "signal strength updated," "signal removed." The current state is a projection over that history.
This is great for durability. You can replay events to reconstruct any past state. You get a full audit trail. You can debug what happened three days ago by literally replaying the history. For the signals that matter (task results, knowledge, feedback), this is exactly what you want.
But the queen's heartbeat signals? The coordination pings? Those are ephemeral by nature. They exist for about 30 seconds, get read by anyone who cares, decay to nothing, and get pruned. Their entire lifecycle is: born, briefly useful, forgotten. Nobody will ever replay a heartbeat signal from last Tuesday.
Here's what the lifecycle of an ephemeral signal looked like in the original design:
- Queen emits a
Coordination signal. Signal bus calls store() on the signal store. LumineDB appends a "signal-deposited" event. Event log grows. - Signal sits in the active signal cache (a DashMap). Workers or nobody reads it.
- Decay tick fires. Signal's strength drops from 1.0 toward zero via exponential decay.
- Signal decays below the pruning threshold. Pruning removes it from the DashMap and calls
remove() on the store. LumineDB appends a "signal-removed" event. Event log grows again.
Steps 1 and 4 both append to the event log. The signal is gone from the active state, but its birth and death certificates live forever in the append-only log. Two events per signal lifecycle, times two signals per second, forever.
The signal was ephemeral. The record of the signal was permanent.
That's the bug. Not in any single component, but in the interaction between an event-sourced store and ephemeral data. The store was designed for data that matters. The signals were data that didn't. Nobody asked whether those two things should live in the same place.
The CPU staircase makes sense now too. Every decay tick, LumineDB queries the event log to rebuild its projection. As the log grows, those queries take longer. More events to scan, more memory to traverse, more CPU per tick. A linear increase in stored events produces a linear increase in CPU cost per operation. Staircase.
Not All Data Deserves to Be Remembered
The fix wasn't complicated once the problem was clear. The real insight wasn't technical. It was philosophical: you have to decide, explicitly, what's worth remembering. If you don't make that decision, your system will remember everything. And everything is expensive.
Formicary already had the concept of signal durability. Every signal type knows whether it's durable or ephemeral. TaskResult, Memory, TaskFeedback, Decision: durable. These are the signals you'd want to replay. Coordination, AgentHeartbeat, AgentAvailable, ResourceClaim: ephemeral. Born, briefly useful, forgotten.
The classification existed. It just wasn't being used. Every signal, durable or ephemeral, took the same path through the same store. The architectural vocabulary was there. The architecture wasn't listening to it.
The fix was three things:
First, durability-aware routing. The CachedSignalStore (which combines a fast cache layer with a durable event-sourced store) now checks signal.signal_type.is_durable() before deciding where to write. Ephemeral signals go to the cache only. Durable signals go to both the cache and LumineDB. The cache is the authoritative source for current state. LumineDB only sees the signals worth remembering.
This single change eliminates roughly 95% of idle event log growth. The queen still emits her heartbeats. They still get stored, read, decayed, and pruned. They just never touch the append-only log.
Second, event log compaction. Even durable signals eventually get pruned. Over long enough timelines, the event log grows for those too. So every 60 seconds, the colony snapshots the active durable signals into a fresh database and atomically swaps it in. Think of it as garbage collection for your event history. The current state survives. The accumulated cruft doesn't.
The implementation uses a tokio::sync::RwLock<Arc<LumineLite>> to make the swap safe. Reads continue against the old database right up until the swap. The new database contains one event per active signal instead of potentially thousands of historical events. Memory reclaimed instantly.
Third, TTL-aware pruning. Every signal has a time-to-live. But pruning only checked whether the signal's strength had decayed below a threshold, not whether it had actually expired. A signal could have a 30-second TTL but hang around at 0.001 strength instead of being cleaned up. Now pruning checks both: if the strength is below threshold or the TTL has elapsed, it's gone.
Three changes. No new concepts. No new dependencies. Just asking the existing architecture to pay attention to distinctions it already knew about.
Your System's Resting State Reveals Its Architecture
I think the most useful lesson here isn't about event sourcing or signal routing. It's about what happens when your system has nothing to do. The idle state is a mirror. It shows you what your system is when you strip away what it does.
When a colony is busy processing tasks, memory growth from ephemeral signals is noise. It's invisible against the backdrop of real work. Task signals, results, feedback, knowledge aggregation. The meaningful data dominates. You'd never notice the heartbeats accumulating underneath.
It's only when the colony goes quiet that the heartbeat becomes the loudest sound in the room. And that's the architectural insight: your system's idle behavior is the purest expression of its overhead. If it's expensive to do nothing, everything you build on top of that foundation inherits that cost.
There's a parallel to how real ant colonies work, which I find kind of poetic. In a real colony, pheromone signals evaporate. They're volatile chemicals. The environment itself handles the cleanup. An ant doesn't need to file a "pheromone-removed" event with a centralized database when a trail fades. The physics of evaporation handles it.
Formicary's original design was like an ant colony where every pheromone molecule was individually cataloged in an archive. Every deposit logged. Every evaporation logged. The ants themselves worked fine. The archivist was drowning.
The fix aligned the digital system with the biological one: let ephemeral things be ephemeral. Let them exist in the volatile cache (the "air"), do their job, and disappear without a trace. Reserve the permanent record for things that actually matter.
I've been building Formicary with an abstraction principle I've written about before: every external dependency should snap on and off without touching your core logic. The SignalStore trait is that abstraction for storage. LumineDB, Bergcache, in-memory, whatever. Snap on, snap off.
That abstraction is exactly what made this fix possible. I didn't have to rewrite the queen. I didn't have to change the signal bus. I didn't have to touch any worker logic. I changed one layer, the composite store's routing logic, and the entire system's idle behavior changed from "drowning in its own paperwork" to "quiet room, lights on, nobody home."
If the storage layer had been hardcoded instead of abstracted, this would have been a multi-week refactor touching every component. Instead it was a few hours and three files.
Abstractions aren't overhead. They're the reason you can fix things like this without burning the house down. But that's a different blog post.
The Takeaway
If you're building event-sourced systems, ask yourself this question early: does every piece of data flowing through my system deserve a permanent record? If the answer is no, build the routing that respects that distinction before your monitoring dashboard gives you a horror story like mine.
The colony runs clean now. Memory flat. CPU flat. The queen still does her job. Workers still stand ready. Heartbeats still pulse through the system. The difference is that the ephemeral stuff stays ephemeral.
Here's what the deploy looked like:
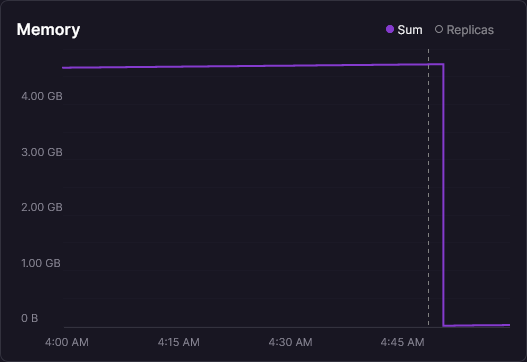
4.5 GB to nothing. One deploy. The compaction ran on startup, snapshotted the handful of active durable signals into a fresh database, and swapped out a week's worth of accumulated event history in a single atomic operation. That cliff is the most satisfying graph I've looked at in a while.
If you're building agent systems, invest in observability. You can't fix what you can't see.